学一学神经网络

学一学神经网络
Kitholt Frank简单学一学神经网络(基于鱼书)
感知机
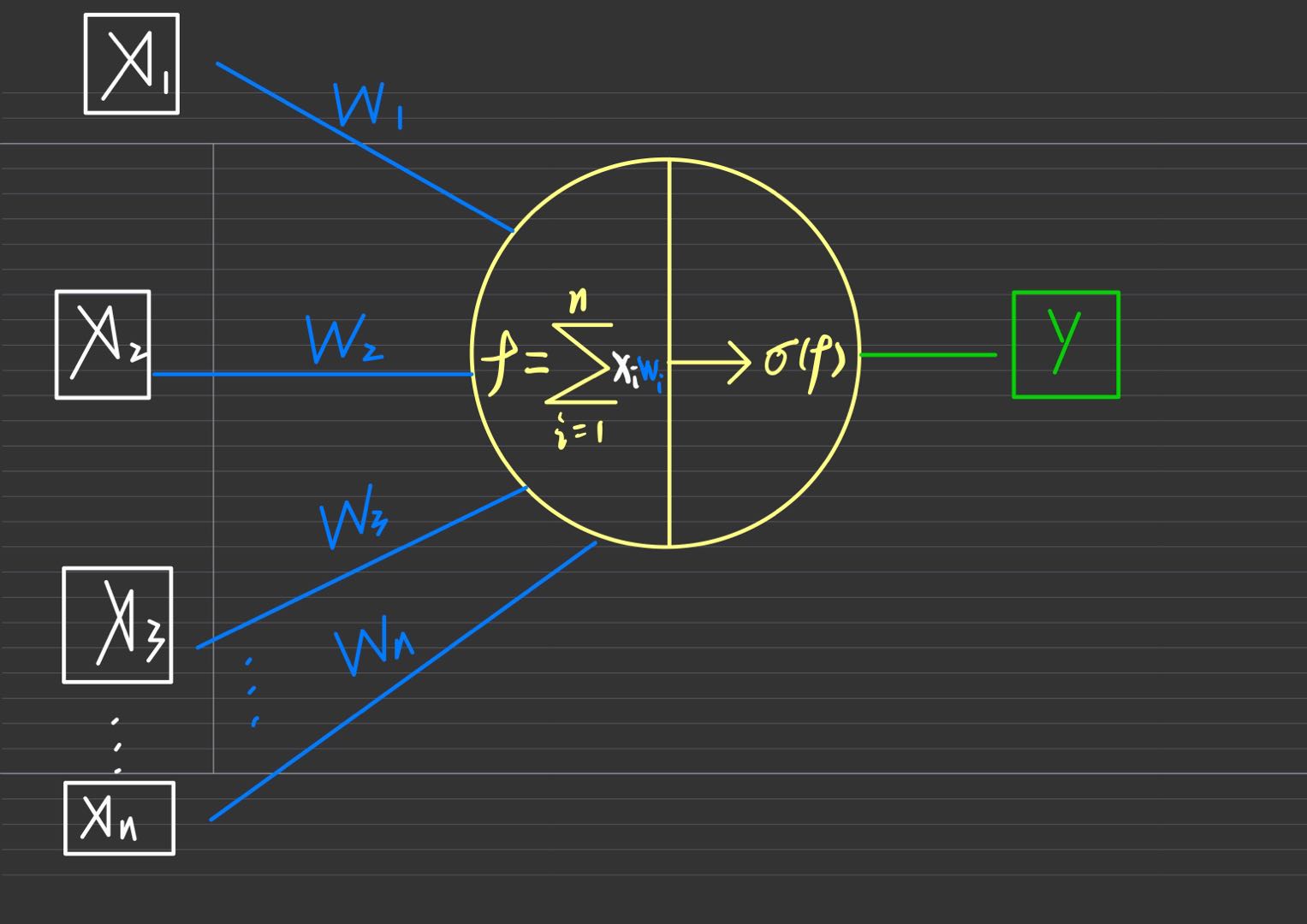
正如图上所示,若干个输入变量通过加权求和,并通过一个跃阶函数的映射,输出结果。在生物学里就是,神经元接收一些信号,然后这些信号会在神经细胞核内进行一系列综合处理,最后当这个处理后的信号达到一定的阈值,该细胞就会被激活,产生一个刺激的输出。这就是所谓的感知。感知机就是对人脑神经元的一次感知模拟。
利用感知机实现简单的逻辑电路
比如实现与门
1 | import numpy as np |
与非门
1 | def NAND(x1, x2): |
或门
1 | def OR(x1, x2): |
可以发现这三种门的实现都是通过一个线性函数来判断的,也就是三种门的解是能被一条直线给划分开的。由一条直线所划分产生的空间称为线性空间。如由曲线划分的则称为非线性空间。
异或门
1 | def XOR(x1, x2): |
经过实验,发现,异或门的实现不能像与门那样,仅仅通过一个线性函数来判断,它的解空间是由一条曲线划分出来的。按照常规的思路,求出这条曲线的表达式就解决了这个问题。通过阅读鱼书可以知道,通过对原有的三种门的叠加(如上代码所示)可以实现异或门。单层感知机解决不了的问题,多层感知机就可以解决。这也间接说明了多层感知机能够去拟合一条曲线!
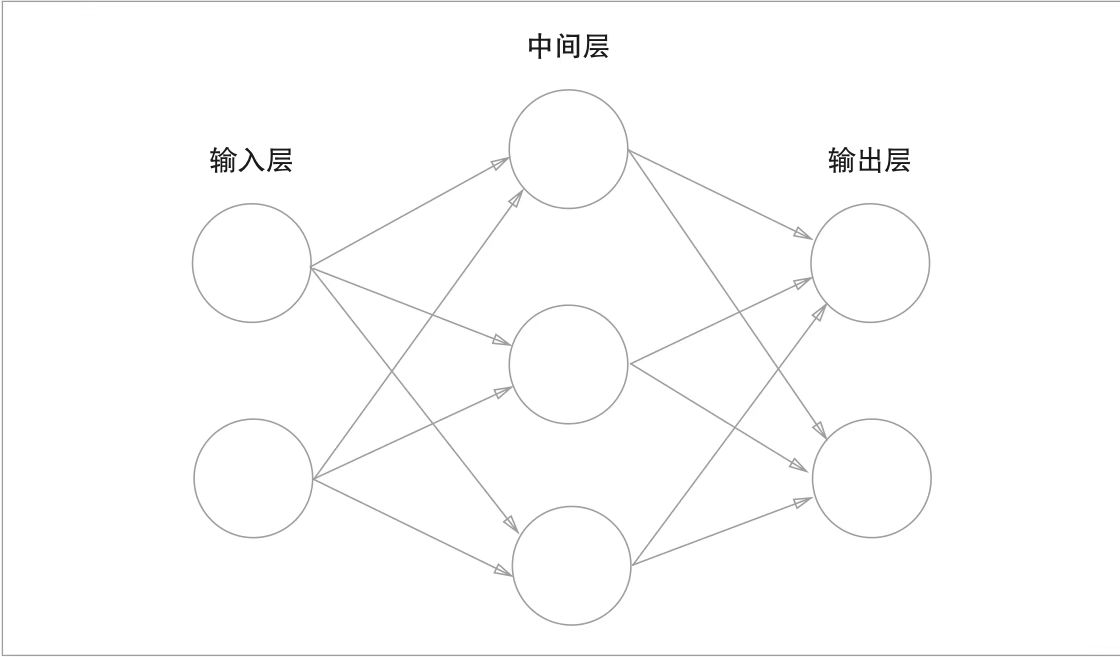
人工神经网络(ANN)AKA 激活函数为非跃阶函数的多层感知机
长啥样以及它的组成成分
激活函数
1 | import matplotlib.pyplot as plt |
1 | #sigmoid函数 |
1 | #修正线性单元ReLu |
1 | #softmax函数(用于多元分类) |
对于softmax函数,在分子分母都乘上C这个任意常数,然后将C移动到指数函数里面(此时里面变成x加上或者减去一个C’),并不会改变运算的结果。为什么要这样子做呢,这是因为指数函数的运算的自变量x如果特别大,会需要特别大的计算量。(指数爆炸嘛)
损失函数
用于衡量神经网络的性能的一项重要指标。所谓损失就是实际结果与理想结果的偏差。比如预测,我们当然希望一次预测成功的几率是100%,现实情况可能是90%,那这个10%就是损失。有n次预测就有n次损失,用一个函数将这些损失表示出来,很明显只要求出这个函数的最小值,就能将损失值降到最低。这也是神经网络优化的目标。那么问题来了,哪些函数可以用来作损失函数?下面给出两个常用的损失函数。
1 | import numpy as np |
1 | import numpy as np |
在定义的交叉熵函数中使用了delta这一变量,是为了防止出现真数为0的情况。(结果为负无穷大)
batch
一批一批地训练样本。比如样本总量500,分成10批,也就是10 batch。
iteration
迭代。1次batch称为1次iteration,可以理解为每10次iteration后权重参数都要进行1次更新。
epoch
时代,纪元。训练集中所有样本全部训练1次称为1个epoch
数值微分(给我狠狠地导!)
利用微小差分求解导数的过程称为数值微分
1 | def numerical_diff(f, x): |
1 | def fun_1(x): |
1 | numerical_diff(fun_1, np.array([0, 0]))#0.0 |
梯度gradient(梯度下降法)
是由一个函数的所有偏导数构成的一个向量,其方向指向函数变化(上升)最快的方向。
1 | #for循环用于求解x每个元素的数值积分,也就是方向导数 |
但是以上求解梯度的代码只适用于参数x是一维数组的情况,下面给出改进后的方法
1 | #首先将W数组和梯度数组全部“碾平”--->1*n的np数组,然后记录W数组一开始的shape,作为最后grad返回的条件判断 |
梯度下降法:随机梯度下降法,批量梯度下降法,小批量梯度下降法
写一个简单的simpleNet类来求梯度,再实现梯度下降法
1 | class simpleNet: |
notes: cross_entropy_error是上文定义好的…
1 | sn = simpleNet() |
1 | def f(W): |
反向传播
有反向传播就有正向传播,正向传播指的是神经网络从输入层到输出层的计算过程。我们都知道这一过程不是百分百完美的,会产生损失。如何修正损失,上文也讲到了—梯度下降法。反向传播其实就是更新迭代权重的过程,它从损失函数的结果出发,求解损失函数关于权重的偏导数,而将这些偏导数组合在一起就是梯度!而实现反向传播的 数学前提则是—链式法则。+
以层为单位实现神经网络的处理(搭建乐高积木)—代码实现
ReLu层
1 | class ReLu: |
Sigmoid层
1 | class Sigmoid: |
softmaxWithLoss层(一般放在输出层)
Affine层(仿射变换层)
正向传播中进行的矩阵乘积运算被称为“仿射变换层”,因为在几何学中,仿射变换包括一次线性变换和一个平移,分别对应神经网络的加权和运算与加偏置运算。
1 | class Affine: |
神经网络的目标—学习!
人的学习是一个无限试错的过程…神经网络的亦是如此。神经网络各个参数(权重,偏置)的初始值取到多少才合适是一个值得研究的问题。如何选取初值?选取了初值后怎么对它们进行迭代更新(梯度更新的方式)。以及超参数的取值和更新问题(比如学习率衰减方法)
权重初始值的设置
如果权重初始值全部设置为0,神经网络将无法进行正常的学习。因为这样子的话,正向传播的结果始终相等,这意味着反向传播的权重更新也是一样的。下面有两种方法来设置权重的初始值…
Xavier初始值
假设当前需要初始化权重的层为A,它与前一层有n个节点连接时,初始值使用标准差1/根号下n的分布
He 初始值
假设当前需要初始化权重的层为A,它与前一层有n个节点连接时,初始值使用标准差根号下n分之2的分布
权重的初始值设置很重要。如果设置不当,会出现“梯度消失”的情况。
权重的迭代更新
也就是要求梯度如何下降?“如何”强调的是方法。下面学习四种方法,它们各有优缺点。
SGD
Momentum

v对应物理上的速度,第二条公式表示物体在梯度方向上受力,物体的速度在增加。
AdaGrad
第一个公式表示某参数的梯度的平方。如果在一次更新中,梯度变化较大,那么h的值也会越大,那在下一次更新中,其学习率会被降低(看第二个公式)
Adam(Momentum + AdaGrad)
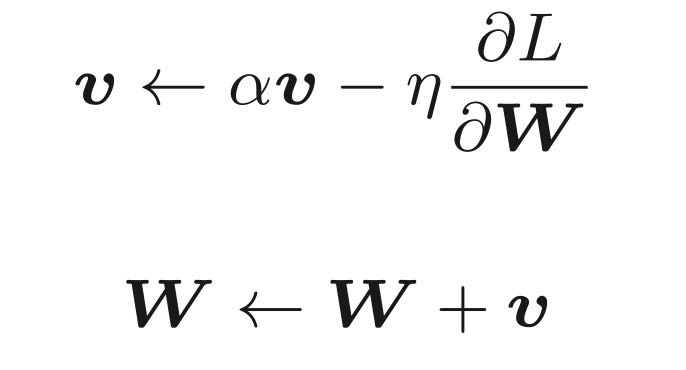
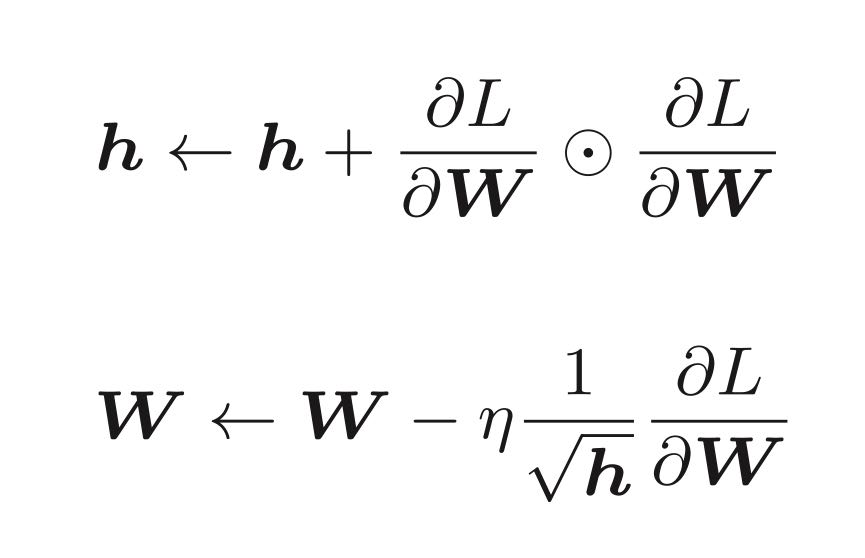
标准(正规)化!
强制调整激活值的分布范围,使每一层的值具有更好的分布广度,如果总是集中在0,1附近,那么在反向传播时会出现梯度消失的情况。
- 使增加学习率(加快学习速度)
- 不再那么依赖初始值(消除量纲影响、较大或较小的数值会对最后加权和结果的影响)
- 抑制过拟合(降低Dropout等的必要性)
正则化!
主要用于避免过拟合的产生和减少网络误差。
权值衰减
给损失函数加上λ*(L2范数),其中lambda表示惩罚系数(权值衰减系数),它的值越大,对权重的惩罚就越大。(通俗理解就是,让权重不敢继续增加)
Dropout
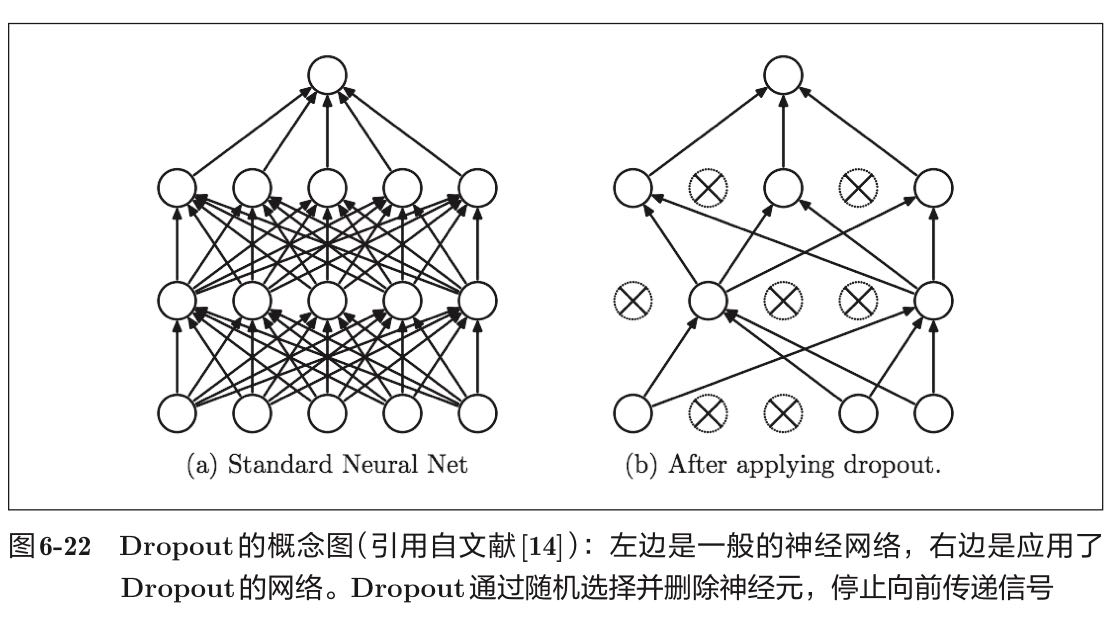
在前向传播过程中,让神经元以一定的概率p停止工作,这样在反向传播的过程中,停止工作的神经元的参数权重就不会被更新。这样就可以使模型泛化性能更强。
关于Dropout的类比(转载自https://blog.csdn.net/stdcoutzyx/article/details/49022443)
虽然直观上看dropout是ensemble在分类性能上的一个近似,然而实际中,dropout毕竟还是在一个神经网络上进行的,只训练出了一套模型参数。那么他到底是因何而有效呢?这就要从动机上进行分析了。论文中作者对dropout的动机做了一个十分精彩的类比:
在自然界中,在中大型动物中,一般是有性繁殖,有性繁殖是指后代的基因从父母两方各继承一半。但是从直观上看,似乎无性繁殖更加合理,因为无性繁殖可以保留大段大段的优秀基因。而有性繁殖则将基因随机拆了又拆,破坏了大段基因的联合适应性。
但是自然选择中毕竟没有选择无性繁殖,而选择了有性繁殖,须知物竞天择,适者生存。我们先做一个假设,那就是基因的力量在于混合的能力而非单个基因的能力。不管是有性繁殖还是无性繁殖都得遵循这个假设。为了证明有性繁殖的强大,我们先看一个概率学小知识。
比如要搞一次恐怖袭击,两种方式:
集中50人,让这50个人密切精准分工,搞一次大爆破。
将50人分成10组,每组5人,分头行事,去随便什么地方搞点动作,成功一次就算。
哪一个成功的概率比较大? 显然是后者。因为将一个大团队作战变成了游击战。
那么,类比过来,有性繁殖的方式不仅仅可以将优秀的基因传下来,还可以降低基因之间的联合适应性,使得复杂的大段大段基因联合适应性变成比较小的一个一个小段基因的联合适应性。
dropout也能达到同样的效果,它强迫一个神经单元,和随机挑选出来的其他神经单元共同工作,达到好的效果。消除减弱了神经元节点间的联合适应性,增强了泛化能力。
随想录
噢,我学了学dropout的相关概念,dropout(层)会舍弃指定比例的神经元,将它们“断电”(不输出),从而提高模型的鲁棒性。(要学习的参数越多,越容易出现过拟合)
哦还有关于中间特征提取的理解,除了第1层的神经元负责接收n维的数据和最后1层的结果层,中间层的每1层的每1个神经元都可以看作是1个学习到的特征,比如中间 某1层 有100个神经元(100个特征),它的下1层有50神经元。(50个特征)
卷积神经网络
卷积层
填充
可以理解为扩充输入数据的大小,比如一个大小为(3, 3)的输入数据,经过填充可变为(4, 4),填充的值可以为任意整数。
卷积运算
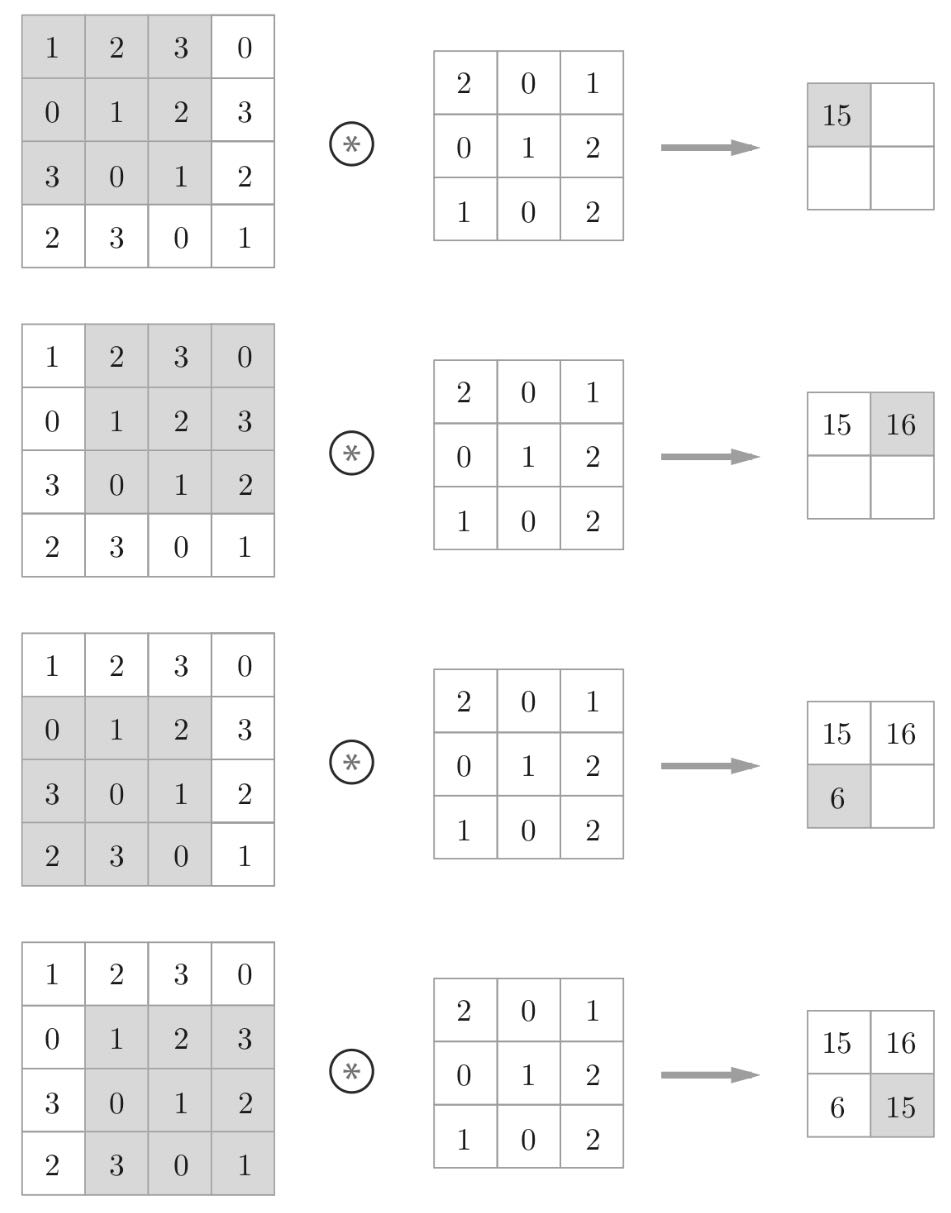
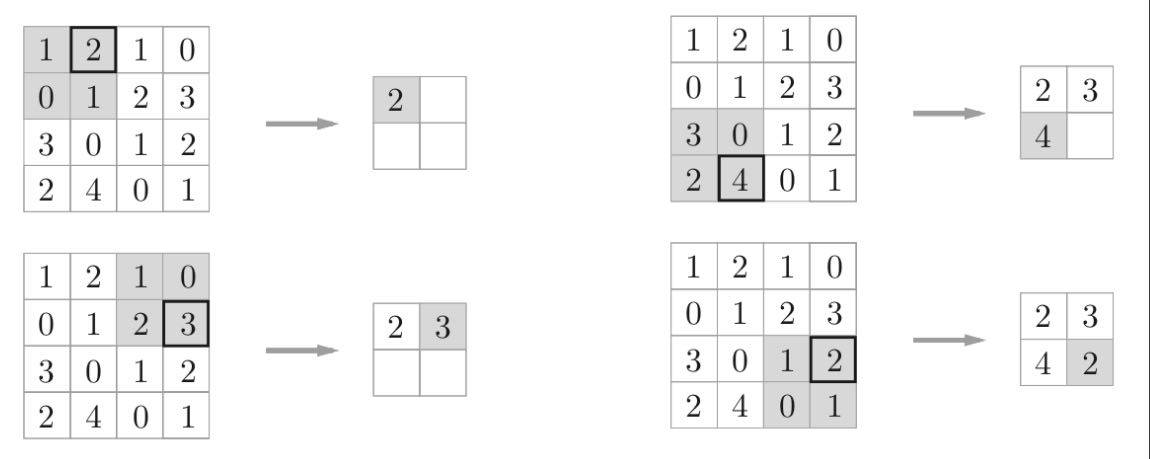
对于输入数据,卷积运算以一定间隔滑动滤波器的窗口并应用(乘积累加运算)。我愿称之为“滑动计算”。
滤波器里面的每个元素就是权重参数。
步幅
也就是上面提到的“一定间隔”,可以理解为步长。
注意:填充的值越大会使输出数据大小越大,而步幅增大则会使输出数据变小。
输入数据为三维数组的书写形式 —> (C, H,W ),对应的维度的滤波器的书写形式 —> (FC, FH,FW )
如果涉及多个滤波器时,则写成(FN,FC, FH,FW )其中FN表示滤波器的数量
池化层
池化是缩小高、长方向上的空间的运算。池化运算也是以一定间隔平滑移动窗口。只不过这个窗口仅仅是一个窗口(没有参数元素,可以理解为一个框框,只是在框框限定的目标区域内进行取最大值【Max池化】或者平均值【Average池化】操作),比如下图给出的则是Max池化。